Introduction
Overview
Teaching: 5 min
Exercises: 10 minQuestions
What are the FAIR principles?
Why should I care to be FAIR?
How do I get started?
Objectives
Identify the FAIR principles
Recognize the importance of moving towards FAIR in research
Relate the components of this lesson to the FAIR principles
What is FAIR?
The FAIR principles for research data, originally published in a 2016 Nature paper, are intended as “a guideline for those wishing to enhance the reusability of their data holdings.” This guideline has subsequently been endorsed by working groups, funding bodies and institutions.
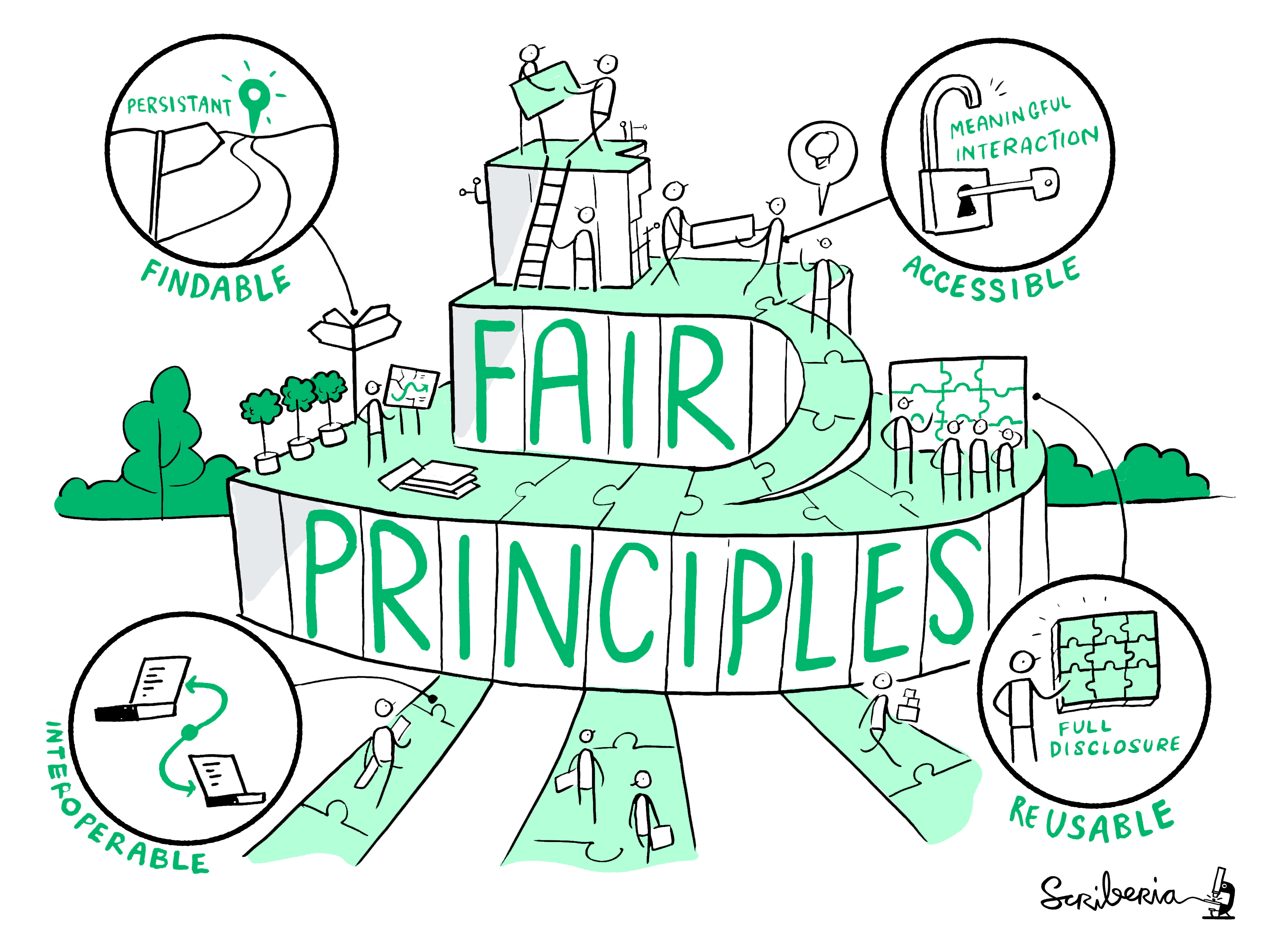
FAIR is an acronym for Findable, Accessible, Interoperable, Reusable.
- Findable: others (both human and machines) can discover the data
- Accessible: others can access the data
- Interoperable: the data can easily be used by machines or in data analysis workflows.
- Re-usable: the data can easily be used by others for new research
The FAIR principles have a strong focus on “machine-actionability”. This means that the data should be easily readable by computers (and not only by humans). This is particularly relevant for working with and discovering new data.
What the FAIR principles are not
A standard: The FAIR principles need to be adopted and followed as much as possible by considering the research practices in your field.
All or nothing: making a dataset (more) FAIR can be done in small, incremental steps.
Open data: FAIR data does not necessarily mean openly available. For example, some data cannot be shared openly because of privacy considerations. As a rule of thumb, data should be “as open as possible, as closed as necessary.”
Tied to a particular technology or tool. There might be different tools that enable FAIR data within different disciplines or research workflows.
 This
image was created by Scriberia for The Turing Way community and is used under a
CC-BY licence. Source: https://doi.org/10.5281/zenodo.3695300
This
image was created by Scriberia for The Turing Way community and is used under a
CC-BY licence. Source: https://doi.org/10.5281/zenodo.3695300
Discuss the different principles
Read the summary table of the 15 FAIR principles in Wilkinson et al. (See “Box 2: The FAIR Guiding Principles”). After reading this, answer the following questions:
- Are there any terms that you are unfamiliar with?
- Are there any principles that you could implement right away?
- What do you think would be the most challenging principle to implement?
Why FAIR?
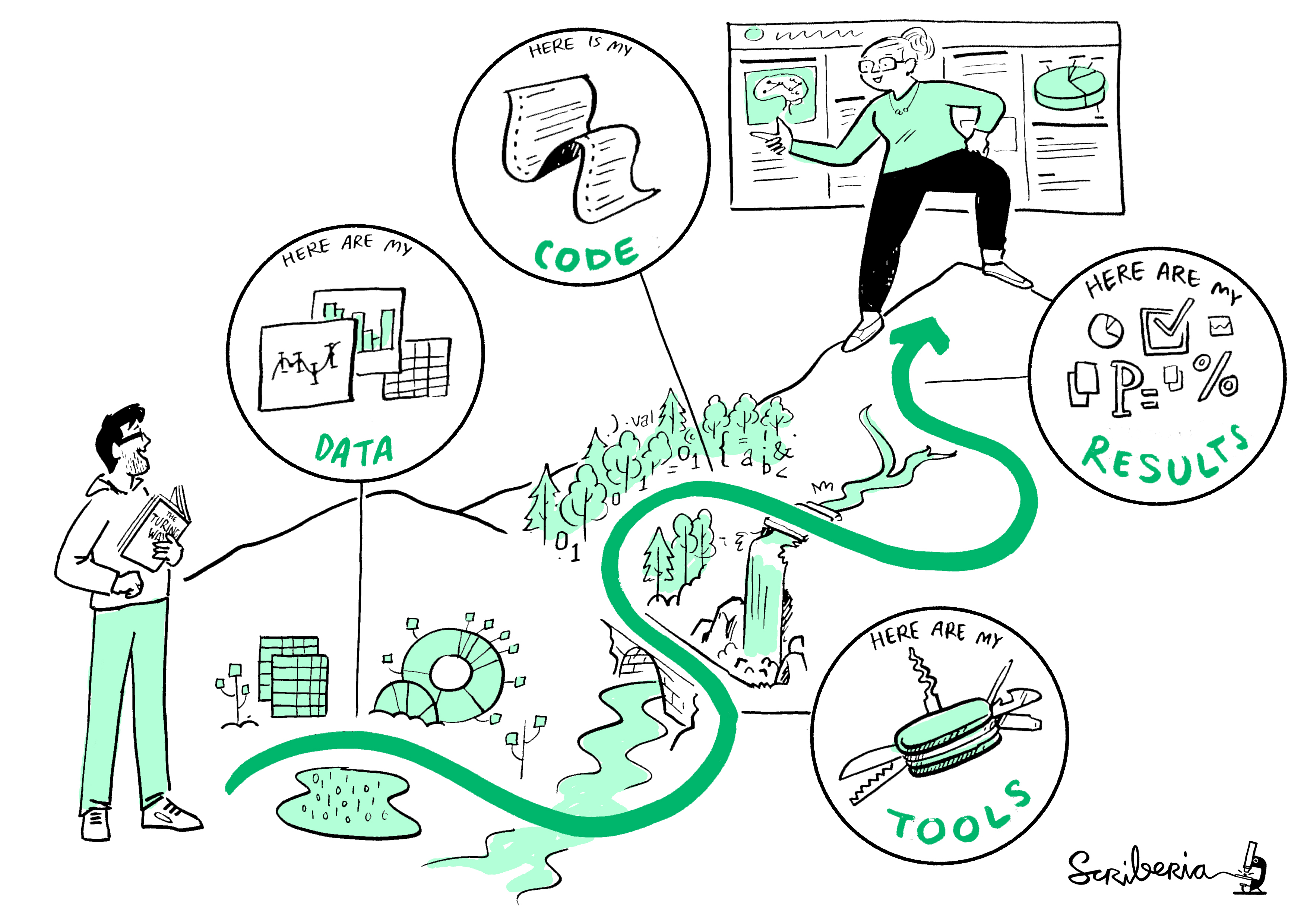
The original authors of the FAIR principles had a strong focus on enhancing reusability of data. This ambition is embedded in a broader view on knowledge creation and scientific exchange. If research data are easily discoverable and re-usable, this lowers the barriers to repeat, verify, and build upon previous work. The authors also state that this vision applies not just to data, but to all aspects of the research process. This is visualized in the image below.
 This
image was created by Scriberia for The Turing Way community and is used under a
CC-BY licence. Source: https://doi.org/10.5281/zenodo.3695300
This
image was created by Scriberia for The Turing Way community and is used under a
CC-BY licence. Source: https://doi.org/10.5281/zenodo.3695300
What’s in it for you?
FAIR data sounds like a lot of work. Is it worth it? Here are some of the benefits:
- Funder requirements
- It makes your work more visible
- Increase the reproducibility of your work
- If others can use it easily, you will get cited more often
- You can create more impact if it’s easier for others to use your data
- …
Getting started with FAIR (climate) data
As mentioned above, the FAIR principles are intended as guidelines to increase the reusability of research data. However, how they are applied in practice depends very much on the domain and the specific use case at hand.
For the domain of climate sciences, some standards have already been developed that you can use right away. In fact, you might already be using some of them without realizing it. NetCDF files, for example, already implement some of the FAIR principles around data modeling. But sometimes you need to find your own way.
This tutorial contains six thematic episodes that cover the basic steps to making data FAIR. We will explain how these topics relate to the FAIR principles, what you can already do today, and where appropriate, we will point out existing standards for climate data.
The episodes are:
- Documentation: helps to make data reusable, especially for humans
- Metadata: similar to documentation, although typically more structured and standardized
- Data formats: highly relevant for interoperability and long-term preservation of data
- Data access: data repositories as well as software can greatly increase data access and findability
- Identifiers: very important for reproducibility, but also for data access and findability
- Licences: well chosen licences facilitate re-use and make sure you get the credits you deserve (if you so desire)
Evaluate one of your own datasets
Pick one dataset that you’ve created or worked with recently, and answer the following questions:
- If somebody gets this dataset from you, would they be able to understand the structure and content without asking you?
- Do you know who has access to this dataset? Could somebody easily have access to this dataset? How?
- Does this dataset needs proprietary software to be used?
- Does this dataset have a persistent identifier or usage licence?
Further reading
- Wilkinson et al. (2016) The FAIR Guiding Principles for scientific data management and stewardship. doi:10.1038/sdata.2016.18
- Mons et al. (2017) Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud. doi:10.3233/ISU-170824
- FORCE11
- GO FAIR initiative
- EU H2020 Guidelines on FAIR Data Management
Key Points
The FAIR principles state that data should be Findable, Accessible, Interoperable, and Reusable.
FAIR data enhance impact, reuse, and transparancy of research.
FAIRification is an ongoing effort accross many different fields.
FAIR principles are a set of guiding principles, not rules or standards.
Documentation
Overview
Teaching: 5 min
Exercises: 15 minQuestions
What is documentation?
Where to document my data?
What is the difference between documentation and metadata?
Objectives
Evaluate existing data documentation with a critical view towards reusability
Ensure that others can re-use your data by writing clear documentation.
What is documentation?
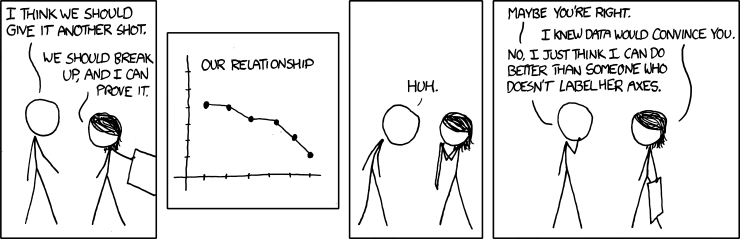 Source: https://xkcd.com/833/
Source: https://xkcd.com/833/
Data documentation is all relevant information needed to properly interpret a dataset. Documentation can be very specific about the data. For example, what does this dataset represent, what units is it in, is it a time average, what is the relation between two data points (subsequent in time, distinct in space, same or different variable), etc. The documentation can also answer some questions about the project: why were the data collected, by whom, and what questions do they address? Was there any kind of quality assurance?
Where to document my data?
Documentation can take many forms: a data management plan, papers published, (jupyter) notebooks, lab journals, provenance information, etc. It is a good idea to bundle these with the data when you publish the data, so that people that find your data will not have to search for it elsewhere, and that access to the documentation is guaranteed. Most data repositories have a ‘description’ field, which is a suitable place to provide any information that is not covered by the other metadata fields.
Grouping related files with Zenodo communities
Data documentation in your project may be scattered over many files of different types. To bundle this information, Zenodo allows you to upload a set of related files (hundreds if needed) as a single dataset.
In addition, Zenodo provides ‘communities’. You can upload all your datasets to Zenodo and add them to a community, thus keeping track of all relevant data for an entire project. You can also track versions. Each dataset gets its own DOI. So you could e.g. cite your data management plan in the description field of your dataset.
What is the difference between metadata and documentation?
Following https://howtofair.dk, we discuss data documentation and metadata separately. However, the distinction between the two is not always clear. In this episode, we will focus on the rich, descriptive kind of documentation that is mostly relevant for human interpretation. In the next episodes, we will focus on more formalized metadata that is also, or even mainly, intended for machine readability.
Exercises
Checking data documentation
Visit a data repository of your choosing (e.g. HydroShare, 4TU.ResearchData, Zenodo, …). Select one or more datasets that you find interesting, and answer the following questions:
- Is the title of the dataset entry in the repository clear and informative?
- Is there a general description of the data?
- Is there a reference to some external documentation of the data (e.g. a journal publication)?
- Would you be able to reproduce the research based on the provided information?
- Would you be able to use this dataset in your own (hypothetical) research project?
- Are contact details provided that you can use in case you have questions?
- Is there any description of the context in which this dataset was created?
- What could be improved about the documentation of this dataset?
Writing your own data documentation
For the real use case you selected in the previous episode, write a general description of the dataset(s) that will be produced. This description may include references to external documents. Also include the steps taken to obtain the final result (‘data flow’). Make sure it will be adequate for others to understand how the data have been created. Also try to formulate a suitable title for the dataset(s).
You may also write down some more technical aspects of the data, such as variable names, units, grids, creation date, software versions, etc.
Limit your description to a single page (max).
Further reading
Key Points
Documentation provides rich contextual information mostly intended for human readers.
Documentation is essential for data reuse and reproducibility.
Metadata
Overview
Teaching: 15 min
Exercises: 15 minQuestions
What are metadata?
What is an ontology or controlled vocabulary?
What are metadata standards?
Objectives
Understand metadata and their role in FAIR data
Recognize different types of metadata
Choose an appropriate metadata standard for your data
Metadata
Metadata are data about data. In other words, metadata is the underlying definition or description of data.
For example, author name, date created, date modified and file size are examples of very basic metadata for a file.
Metadata make finding and working with the data easier. Therefore, they are essential components in making your data FAIR. One could argue that metadata are more important than your data. Without metadata, the data would be just numbers. But, without the original data, the metadata can still be useful to track people, institutions or publications associated with the original research. From a FAIR perspective, metadata would always be openly available.
Metadata can be created manually, or automatically generated by the software or equipment used and preferably according to a disciplinary standard. While data documentation is meant to be read and understood by humans, metadata are primarily meant to be processed by machines. There is no FAIR data without machine-actionable metadata.
FAIR principles about metadata
Let’s have a look at FAIR principles.
- Which principles focus on metadata?
Solution
Because metadata are data about data, all of the principles i.e. Findable, Accessible, Interoperable and Reusable apply to metadata.
Three types of metadata
We focus on three main types of metadata:
-
Administrative metadata helps manage a resource or a project and indicates when and how the data were created. For example, the project/resource owner, principal investigator, project collaborators, funder, project period, permissions, etc. They are usually assigned to the data before you collect or create them.
-
Descriptive or citation metadata help to discover and identify data. A very good example of these are keywords, which are often added to data or publications with the only purpose to make them more findable (i.e. with a search engine). Other examples are the authors, title, abstract, keywords, persistent identifier, related publications, etc.
-
Structural metadata describe how a dataset or resource came about, but also how it is internally structured. They address the ‘I’ and ‘R’ in FAIR. For example, measurement units, data collection method, sampling procedure, sample size, categories, variables, etc. Structural metadata have to be created according to best practices in a research community and will be published together with the data.
Keep your metadata up-to-date!
- Descriptive and structural metadata should be added continuously throughout the project.
- Different types of metadata apply not only to a database, but also to individual sets of data, e.g. images/plots, tables, files, etc.
Types of metadata for geospatial data in your community/research team
Here are some questions about the use case you chose in the introduction of this tutorial, here.
- What is the type of metadata in your use case?
- What information are described by that metadata?
Ontology
An ontology (or controlled vocabulary) is a standard definition of key concepts in your community/research team and focuses on how those concepts are related to one another. A controlled vocabulary is a set of terms that you have to pick from. Using an ontology:
- helps others to understand the structure and content of your data,
- makes your data findable, interoperable and reusable.
A controlled vocabulary for climate and forecast data
In climate-related domains, many variables depend on the type of surface. How can you specify the surface type in the metadata?
Solution
Climate and Forecast metadata (CF conventions) maintains a vocabulary specifically for specifying surface and area types. The vocabulary is available on the CF site as the Area Type Table.
Metadata standards
A metadata standard (or convention) is a subject-specific guide to your data. Rules on what content must be included, which syntax should be used, or a controlled vocabulary are included in a metadata standard. The quality of your metadata has a huge impact on the reusability of your research data. It is best practices to use metadata standard and/or an ontology commonly used in your community/research team.
Some of the recognized metadata standards for climate-related domains are:
- Climate and Forecast metadata (CF conventions)
- World Meteorological Organization Core Metadata Profile (WMO-CMP)
- Generic Earth Observation Metadata Standard (GEOMS)
- Cooperative Ocean-Atmosphere Research Data Service Conventions (COARDS)
- Water Markup Language (WaterML)
- Shoreline Metadata Profile of the Content Standards for Digital Geospatial Metadata (SMP-CSDGM)
A recognized metadata convention for climate data
Let’s do a search for the keyword
climatein FAIR standards.
- Which metadata convention did you find?
- Which file formats allow you to include the metadata?
- What are other domains that use this convention?
Solution
- Climate and Forecast metadata (CF conventions)
- NetCDF
- Atmospheric science, earth science, natural science, and oceanography
No/incomplete metadata standards in your research team
Imagine you are working in a lab, and you want to use metadata describing processes that produce data. However, the available standards in your research team are not specifically suited for that purpose.
How can you define a relevant metadata scheme? What would you do if there was no standard in your research team?
Sensitive data
You cannot openly publish sensitive data. However, you can always publish rich metadata about your data. Publishing metadata helps you to make clear under which conditions the data can be accessed and how they may be reused.
Key Points
From a FAIR perspective, metadata are more important than your data.
Metadata are preferably created according to a disciplinary standard.
To be FAIR, metadata must have a findable persistent identifier.
File format
Overview
Teaching: 15 min
Exercises: 20 minQuestions
What is a file format?
What file formats should I use?
Objectives
Name common formats used in climate-related domains.
Understand different types of data.
Choose correct file formats for your work.
File format
A file format is the structure of a
file. It determines how the data within the file is organized. Files are usually
named as filename.format. For example, climate.jpeg is a file named climate
with jpeg format. You might know that
jpeg is a commonly used format for digital images. Therefore, the file
climate is probably an image.
Each file type like images, video, and text can be stored in several formats.
For example, climate.jpeg, climate.png, and climate.gif. All file formats
are used to store image data, but they have differences in compression,
available colors, resulting filesize, etc (for more information see this
page).
When deciding which one to use, it’s important to note the advantages and
disadvantages of each.
Also, formats may be dependent on particular software. When data is stored from a software program, it is usually saved in that program’s standard file format. One example is creating tabular data using spreadsheet software. Tabular data have specific properties that are better supported by the spreadsheet software than a word processor.
No extension or multiple extensions!
In UNIX-like operating systems, a file can have no extensions, or more than one extension. For example, in
filename.tar.gz, the.tarindicates that the file is a tar archive of one or more files, and the.gzindicates that the tar archive file is compressed with gzip. Also, programs reading files usually ignore the format; it is mostly intended for the human user. In Windows, a file should have at least one extension.
File formats for geospatial data in your community/research team
Here are some questions about the use case you chose in the introduction.
- What is the format of the geospatial data?
- Do you know why the data is in that format?
This is what go-FAIR.org has to say about Format
- I1:(meta) data use a formal, accessible, shared, and broadly applicable language for knowledge representation. For example, if data is provided in commonly understood and preferably open formats.
- R1.3: (meta)data meet domain-relevant community standards e.g. those for data formats.
Recommended formats for different types
There are several data types like geospatial, tabular, storyline, documentation and paper, textual, video/audio, and image/figure. Some of them are more in line with the FAIR principles than some others. Here are some recommended formats for different types:
| Data type | Data format |
|---|---|
| Geospatial data | NetCDF |
| Tabular data | SQLite |
| Textual data | Markdown |
| Image data | TIFF 6.0 uncompressed |
| Audio data | Lossless Audio Codec (FLAC) |
| Video data | MPEG-4 |
| Documentation | Microsoft Word or PDF |
| Papers & Articles | LaTeX |
| Storyline Definitions | JSON |
Other data types
Have a look at the list of the recommended formats for different types (mentioned above) and pick a data type.
- What are the other formats for the type that you selected?
- Which of those formats are common in your community?
- Discuss some of the advantages and disadvantages of those formats.
Data Management Plan
Data Management Plan (DMP) covers how data can be stored, described and reused. For example, see DMPonline or DSW.
Different formats for different purposes
In the previous sections, we learned that different file formats have different properties. The purpose of a file should help determine which file format to choose. In the example of creating tabular data using spreadsheet software, there is no guarantee that the tabular data can be used or displayed in the future. Because the software can become obsolete or only support a specific version of formats.
It is good to plan at the beginning of your project, what file formats to use for each purpose:
- data collection / processing / analysis,
- reuse: the longer you want to use the data, the more you have to use open, standard and well-documented file formats to avoid obsolescence.
- preservation: many journals, archives and data repositories require that data are uploaded in certain file formats. Therefore, you may have to keep some data files in multiple formats.
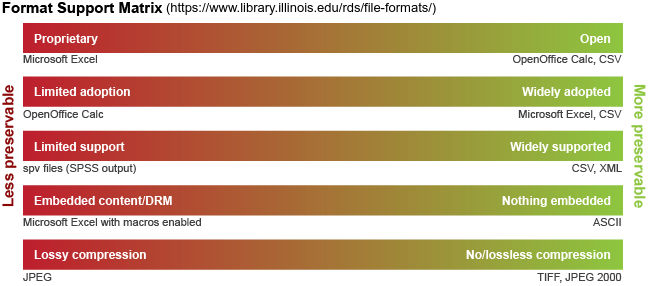 If we
store the data in a more open or widely supported format, it will have the
greatest re-usability in the future.
If we
store the data in a more open or widely supported format, it will have the
greatest re-usability in the future.
Non/proprietary format
File formats may be either proprietary or non-proprietary (open or free):
The proprietary format is owned by a company, organization or individual. Their specifications are usually not publicly available and the risk of obsolescence is high. If you want to store data in a proprietary format for a reasonable time, consider including a readme.txt file that documents the name and version of the software used to generate the file, as well as the information of the company that made the software.
The open format is a file format that is published and free to be used by everybody.
Good practice for format selection
We want to create a checklist for choosing a format that improves the FAIRness of the data. What items should be included?
Solution
- non-proprietary
- open or widely supported format
- standard and well-documented
- supports relevant metadata
- commonly used by your research community
Common file formats for geospatial data
In climate-related domains e.g. weather and climate science, earth observation science, or hydrology, data can be in many types and for different purposes. In this section, we will introduce some common and acceptable data formats.
NetCDF:
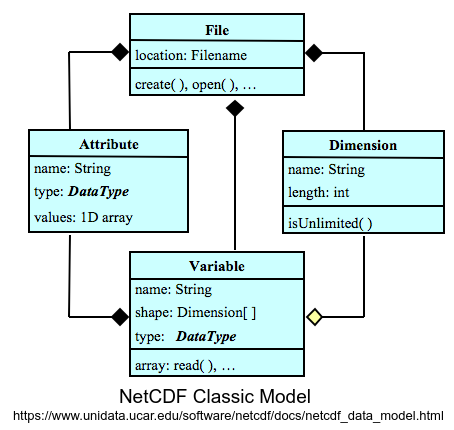
NetCDF was originally developed for the Earth science community, but it can be used for many kinds of data. It views the world of scientific data in the same way that a geo-scientist might: there are various quantities such as temperature or elevation located at points at particular coordinates in space and time. The quantities (here temperature or elevation) are stored as netCDF variables whereas coordinates information is stored as netCDF dimensions. The metadata, such as the units, is stored as netCDF attributes.
GRIB:
GRIB stands for general regularly-distributed information in binary. It is commonly used by the World Meteorological Organization (WMO) for weather model data. It is also used operationally worldwide by most meteorological centers, for Numerical Weather Prediction output. Some of the second-generation GRIB are used in Eumetcast of Meteosat Second Generation. Another example is the North American Mesoscale model.
GeoTIFF:
GeoTIFF is a standard image file format to describe and store raster image data with geographic information. So it can be used by Geographic Information System (GIS) applications. It is suitable for a wide range of applications worldwide. For example, satellite imaging systems, scanned aerial photography, scanned maps, digital elevation models, or as a result of geographic analyses. As an example, GeoTIFF 1.1 is an approved NASA Earth Science Data Systems standard (see NASA Standards and Practices).
HDF5:
The Hierarchical Data Format Version 5 (HDF5) implements a model for managing and storing data, developed by the National Center for Supercomputing Applications (NCSA). HDF5 is a general-purpose, machine-independent standard for storing scientific data in files. An HDF5 structure is self-describing, allowing an application to interpret the structure and contents of a file without any outside information. As an example, NASA’s Earth Observing System, the primary data repository for understanding global climate change uses HDF5, for more information see this page.
Other formats for geospatial data
There are many other formats to store geospatial data like SHP(shapefiles) for vector data, DBF(database file), and NetCDF ZARR Data, etc.
Select a data format
Let’s have a look at case-study that you selected in introduction of this tutorial, here. Assume that the authors want to publish their data. What suggestions would you give the authors for data format?
Key Points
Choose formats that are common to your field/community to ensure the interoperability and reusability of your data.
Make sure that the file formats you choose can hold the necessary data elements and information.
Decide on how long do you intend to preserve your data.
Make sure to check requirements of the repository where data is stored.
Access to the data
Overview
Teaching: 10 min
Exercises: 15 minQuestions
What is meant by ‘accessibility’?
What are relevant data repositories in climate science?
How to choose a data repository?
Objectives
Identify suitable repositories to make your research data acessible.
Plan access to the data in a data management plan.
What is access to data?
Accessibility addresses the A in the FAIR principles. Once the user finds the required data, she/he needs to know how can they be accessed, possibly including authentication and authorisation. Accessible data objects can be obtained by humans and machines upon appropriate authorisation and through a well-defined and universally implementable protocol. In other words, anyone with a computer and an internet connection should be able to access at least the metadata.
This is what go-FAIR.org has to say about Accessible
- A1. (Meta)data are retrievable by their identifier using a standardised communications protocol
- A1.1 The protocol is open, free, and universally implementable
- A1.2 The protocol allows for an authentication and authorisation procedure, where necessary
- A2. Metadata are accessible, even when the data are no longer available
Accessible does not mean open without constraint
Accessibility means that the human or machine is provided - through metadata - with the precise conditions by which the data are accessible and that the mechanisms and technical protocols for data access are implemented such that the data and/or metadata can be accessed and used at scale, by machines, across the web.
FAIRness in climate science
Although FAIRness in climate science is advancing and some clearly accessible repositories exist, it is still also common practice to only make a dataset accessible via the project website. Because projects do not last for ever, some of these websites are not maintained, resulting in inaccessible datasets.
Next to large-scale general-use repositories such as Zenodo, there are also several domain-specific repositories. You may be familiar with ESGF, CDS, or Climate4Impact.
Stages of accessibility
You submitted a paper, and the reviewer asks you to make your data accessible. You consider your options,
- You make a note in your paper that data can be requested by sending you an email
- You provide the data as supplementary information to your paper
- You upload the data to some cloud storage and put a shareable link in your paper
- You upload the data to a university drive and request a DOI from the library
- You upload the data to a generic repository such as zenodo
- You upload the data to a domain-specific repository such as Hydroshare
Describe which of these are adhering to the FAIR principles, focusing on the findability and accessibility criteria.
Solution
F1 F2 F3 F4 A1 A1.1 A1.2 A2 Verdict 1. 😢❌ 😢❌ 😢❌ 😢❌ 😢❌ 😢❌ 😢❌ 😢❌ Hard to find and difficult to access. 2. 🤔❓ 🤔❓ 😢❌ 😢❌ 😢❌ 🤔❓ 🤔❓ 😢❌ Data may be found indirectly through the papers DOI, but there is no clear access protocol. 3. 😢❌ 🤔❓ 🤔❓ 🤔❓ 😢❌ 🤔❓ 🤔❓ 😢❌ Both data findability and accessibility will certainly take (human) effort. 4. 🥳✔ 🤔❓ 🤔❓ 🤔❓ 🥳✔ 🥳✔ 🥳✔ 🤔❓ This could probably work if the university offers enough support. 5. 🥳✔ 🥳✔ 🥳✔ 🥳✔ 🥳✔ 🥳✔ 🥳✔ 🥳✔ The best solution if there is no suitable domain-specific repository. 6. 🥳✔ 🥳✔ 🥳✔ 🥳✔ 🥳✔ 🥳✔ 🥳✔ 🥳✔ The additional focus makes it even easier for you to describe your data according to the relevant standards, and for others to find it.
Data repositories
Let’s examine a couple of different data repositories (maybe datasets in different repos?) For each of the following, Zenodo, ESGF, CDS, answer the following questions:
- Is this repository publicly accessible?
- Is it free?
- Is it proprietary?
- Does it allow for authentication?
- Is there any quality control for this repository?
- Are metadata accessible, even if the data is not?
- How long will the data be maintained?
- Is there any backup system in place?
- Is it easy to find data that is stored in this repository?
- Is it easy to download data from this repository?
- Is it easy to upload data to this repository?
Solution
Zenodo ESGF CDS 1. Is this repository publicly accessible? 🙂Most (meta)data are publicly accessible, but there are also close/restricted datasets. 🥳Yes but account registration is required. 🥳Yes but account registration is required. 2. Is it free? 🥳✔ 🥳✔ 🥳✔ 3. Is it proprietary? 🥳No. Non-proprietary format is mandatory on Zenodo. 🥳No. Data are mostly available in NetCDF format. 🥳No. Most datasets are in NetCDF or GRIB format. 4. Does it allow for authentication? 🙂A light authentication mechanism, such as a token (via OAuth 2.0 access token), is acceptable in some certain cases, e.g. high-traffic access. This authentication is acceptable as long as there is a totally open/anonymous route too. 🙂ESGF uses the OpenID and OAuth2 authentication system. Login credentials are required. An open source authentication client is also available. 🙂CDS uses its own API and authentication key. Login credentials are required. The API is open source. 5. Is there any quality control for this repository? 🙂Although not mandatory, it is highly recommended by Zenodo to include qualified references to other (meta)data. This is a quite common practice on Zenodo. 😢Citation links and references are usually missing for many datasets. 🙂Quite some datasets are provided with citation/reference information. 6. Are metadata accessible, even if the data is not? 🙂Yes for some datasets which apply this principle. 🤔Unknown. 🤔Unknown. 7. How long will the data be maintained? 🥳Lifetime of the host laboratory CERN. 🤔Unknown. 🤔Unknown. 8. Is there any backup system in place? 🥳12-hourly backup for Metadata and persistent identifiers. 🥳Yes. Subsets of the data are replicated at Lawrence Livermore National Laboratory (LLNL) for backup. 🥳Yes for at least all ECMWF data. 9. Is it easy to find data that is stored in this repository? 🥳Yes. All data are findable via DOI and well documented. There are also plenty filter available for searching. 🤔PID is assigned per dataset. But the UI for data browsing is not friendly. Although metadata are provided, the datasets lack documentation. 🥳Yes. All data are findable via DOI. The documentations are rich. The searching UI is quite friendly. 10. Is it easy to download data from this repository? 🥳Yes for data with open access. 🥳Yes. 🥳Yes. 11. Is it easy to upload data to this repository? 🥳Yes. Although one should use a Zenodo account, or an GitHub account, or an ORCID account. 🤔In principle yes, but the procedures are complicated. To upload data to a certain project, one need a manual approval on joining that project. 🤔In principle yes, but the procedures are complicated. One needs to contact Copernicus Climate Change Service (C3S) and fill in a confirmation form first.
What about your data?
When it comes to making data accessible, there are some easy steps that can by applied by any researcher to their own data. Some steps, however, have to be developed accross a scientific domain. Particularly, the establishment of domain-specific data repositories.
- What is the status in your specific (sub-)domain?
- Are there suitable repositories?
- Are they easy to use? What are the advantages/disadvantage?
Key Points
Accessible does not mean open without constraint.
Metadata can still be accessible, even if the data itself is not (anymore).
EU-funded projects are expected to make generated data accessible to the public.
Persistent identifiers
Overview
Teaching: 10 min
Exercises: 5 minQuestions
What is a persistent identifier (PID)?
Which data need a PID?
How do you get a PID?
Objectives
Obtain a PID for your data
What is a persistent identifier?
Persistent identifiers (PIDs) are required to address the F in FAIR. They are used to identify digital resources using a unique and standardized label. PIDs are persistent, meaning that we will be able to find the data long into the future, even if the actual location (e.g. URL) or name of the resource changes. Well known PIDs are the digital object identifiers (DOI) and the Handle System. In fact, a DOI is a type of Handle System handle.
Assigning a PID to your data makes sense. It will make the data easier to find, promotes reproducibility and reuse, makes it possible to track the impact, and enables long-term availability of the data.
Anatomy of a DOI
A DOI takes the form of a string with two parts, a prefix and a suffix, divided by a slash. Usually, a prefix corresponds to the publisher, and the suffix to the resource.
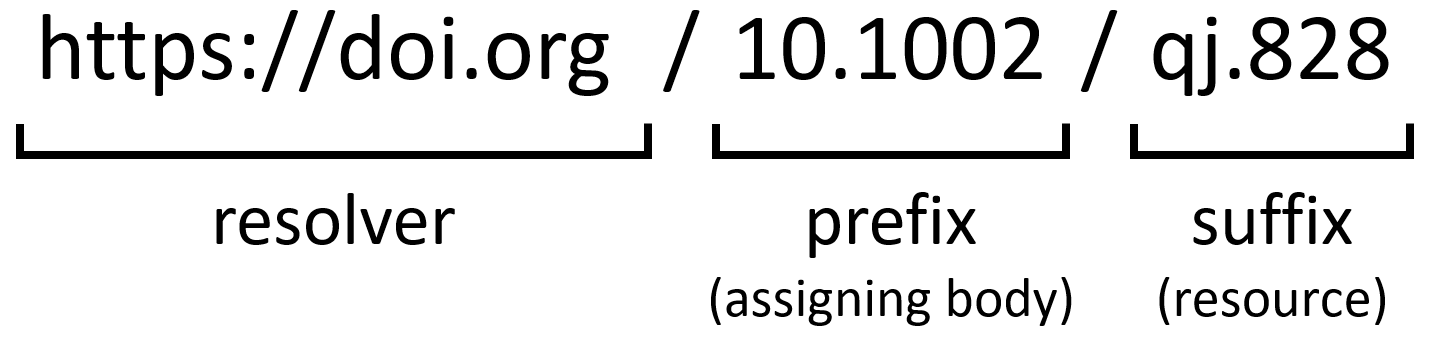
Exercise
- Where does the above linked DOI point to?
- Do you think this DOI will still be valid in 50 years?
- Who is responsible to update the DOI if you get a dead link?
- What do you think should happen if the journal ceases to exist?
Solution
- The DOI above points to an article: The ERA‐Interim reanalysis: configuration and performance of the data assimilation system, by D. P. Dee et al.
- I expect the DOI to be valid, but not the URL it pointing to.
- The journal who registered the DOI, in this case Royal Meteorological Society, should update the URL linking to the DOI. DOI itself is persistent.
- If the journal ceases to exist, one can still access the metadata assigned to this DOI. With this metadata, e.g. the author list or linked publications, it may still be possible to retrieve this paper from other resources.
Which data need a PID?
Ideally, all research objects (publications, software, observations, model output, figures, etc.) have PIDs, so that the entire workflow can be traced through the links between them. Additionally, it often makes sense to make separate entries for raw and processed data.
Making raw data available enables other researchers to re-use your data, and to develop their own models and ideas. Making the processed data available serves to promote reproducibility, and enables others to build upon your results. In climate science the large intercomparison projects are a prime example of the latter.
One of the challenges is how to deal with ‘dynamic data’, which is also highly relevant for climatological data. How do you make PIDs for data that is continuously evolving? For the CMIP6 project, a pragmatic approach was taken, consisting of a global PID for the entire, evolving data superset, and specific PIDs for citing specific subsets.
Discussion
Consider your own use case (that you selected in episode 1):
- Is there any input data? Does it have a DOI?
- Is the output data part of a (large) project that has some central policy on DOIs (such as CMIP6?)
- Did you (or do you plan to) make a DOI available for the (anticipated) output data?
- Why/Why not?
How do you get a PID?
Getting a PID (usually a DOI) for your data is as easy as publishing your data to a data archive. After the upload, a PID is automatically assigned. Note that just getting a PID is not all for making the data FAIR. Without metadata it will still be difficult to find the data. That’s why many data archives make it easy to add metadata, such as a list of authors, related projects, linked publications or other related items.
Below you will find a list of resources to find a trusted or recommended repository.
-
OpenAIRE: Find the appropriate repository to deposit your research products of any type (publication, data, software, other) or to include in your data management plan. Search and browse for OpenAIRE compliant repositories registered in OpenDOAR and re3data. OpenAIRE is an EC funded network of Open Access repositories, archives and journals that support Open Access policies.
-
Zenodo: Zenodo is a general-purpose open-access repository developed under the European OpenAIRE program and operated by CERN. It allows researchers to deposit data sets, research software, reports, and any other research related digital artifacts.
-
FAIRsharing catalogue of databases: FAIRsharing is a web-based, searchable portal of three interlinked registries, containing both in-house and crowdsourced manually curated descriptions of standards, databases and data policies, combined with an integrated view across all three types of resource.
-
Registry of Research Data Repositories (re3data.org): re3data.org is an Open Science tool that offers researchers, funding organizations, libraries and publishers an overview of existing international repositories for research data.
-
European Research Council (ERC) Open Access: ERC curated webpage on policies on open access and data storage, including a list of recommended repositories.
Linked data
Remember that we said that data should be fair to computers? By assigning PIDs to our datasets (and publications), large networks of linked data and information can be created automatically.
Further Reading
- https://www.go-fair.org/fair-principles/f1-meta-data-assigned-globally-unique-persistent-identifiers/
- https://librarycarpentry.org/lc-fair-research/02-findable/index.html
- https://datascience.codata.org/articles/10.5334/dsj-2017-030/
Key Points
Promote reproducibility by assigning persistent identifiers to your processed data.
Promote reuse by adding a persistent identifier to your raw data.
If your data do not have a PID, they will not be FAIR!
Data licenses
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What is a data license?
Which data license should I use for climate data?
What are the consequences of (not) using a data license?
Who decides which license I can use?
Objectives
Find existing license policies that may apply to your data
Choose a suitable license given these constraints
Apply a license to your data
General info on licenses
Let’s get started with a small exercise.
Choosing a license
Go to https://chooser-beta.creativecommons.org/ and follow the steps.
- What license did you arrive at?
- Does the license fit with the FAIR principles?
- Discuss.
One of the key parts of FAIR data is that they are reusable not only practically, but also legally. By attaching a license to your work, you specify who can reuse your data, for which purposes, and what should be done with derived work. Creative Commons (CC) are the most used license in research. They are widely recognized, easy to apply, and juridically sound. The CC license is built on four cornerstones:
- Attribution (BY): Credit must be given to you, the creator.
- Share-Alike (SA): Adaptations must be shared under the same terms.
- Non-Commercial (NC): Only noncommercial use of your work is permitted.
- Non-Derivative (ND): No derivatives or adaptations of your work are permitted.
The six CC licenses are combinations of these cornerstones.
Note
Without a license you keep the copyright to yourself. This prohibits anyone from using the data for their own work.
These are some points to consider when choosing a license:
- A license cannot be revoked once the data has been shared.
- As the original author, you can change the license for future publications.
- Sensivite data / embargo
- The less restrictions you add to your data, the more it can be re-used
Further reading:
- https://www.dcc.ac.uk/guidance/how-guides/license-research-data
- https://www.openaire.eu/research-data-how-to-license/
Discussion
- When was the last time you published some data?
- What license did you distribute it under?
- Where did you share the data?
licenses in Geoscience
In general, data sources in geoscience such as CMIP5 and CMIP6 are available under FAIR licenses. That is, you can freely use the data, but there are still some requirements. For example, if you base your research on CMIP6 data, you must give proper credit to the project if you deposit your research data somewhere. This is specified in the Terms of Use.
You can find the Terms of Use for some widely used projects here:
- CMIP6: https://pcmdi.llnl.gov/CMIP6/TermsOfUse/TermsOfUse6-1.html
- CMIP5: https://pcmdi.llnl.gov/mips/cmip5/terms-of-use.html
- CORDEX: http://is-enes-data.github.io/cordex_terms_of_use.pdf
Discussion
- How do the terms of use for CMIP6 data differ from the Creative Commons licenses?
- Can you reshare the data?
- Should you attribute the authors of the data? If so, how?
- Can derived data be used commercially?
- Can you find additional terms of licenses that are applicable to your situation?
- FIXME: check what the answer should be
Further reading:
Data ownership
One of the major challenges with data licenses is data ownership. Who actually owns the data? Can other parties use the data and what control do you have over the data as the owner? These points are addressed by the license file.
For any academic institute, there are three possible owners of the data:
- You
- Institute you work for
- Funding agency
Data ownership is defined in the data management plan. You may be restricted by your institutions’ policies on licenses.
Excercise
Take a few minutes to find out whether your institute has a license policy.
- What does it say?
- Who owns your data?
- What do you do if your institution does not have a policy?
Excercise
Imagine, some researchers have SOME CRAZY EXAMPLE
They have deposited the data on their institute’s website under the data under CC-BY 4.0.
- Do you see any problems with the license they chose?
- Which data license should you put on it when you distribute the data?
- Which license can you not put on it when you distribute the data?
What does the EU require?
The European Commission has fully embraced FAIR principles. Horizon2020 already mandates open access to all scientific publications, and is now running a pilot from 2017 for research data to be open by default with possibilities to opt-out.
How the data will be licensed is part of the data management plan. Specifically:
- How will the data be licensed to permit the widest re-use possible?
- When will the data be made available for re-use (i.e. are the data under embargo)?
- Are the data usable by third parties (i.e. are there restrictions)?
Excercise
Which license does the European Commission recommend for data acquired under the Horizon 2020 Programme?
Solution
The European Commission encourages researchers to provide access to their data in the broadest sense. They encourage authors to retain their copyright, but grant adequate licenses to publishers. They recommend the Creative Common licenses as a useful legal tool for providing open access.
Further reading:
- https://ec.europa.eu/research/participants/docs/h2020-funding-guide/cross-cutting-issues/open-access-data-management/open-access_en.htm
- https://ec.europa.eu/research/participants/data/ref/h2020/other/hi/oa-pilot/h2020-infograph-open-research-data_en.pdf
- In case you are really interested, have a look at p251-253 of the Horizon2020 Programme
How are licenses applied to research data?
In principle, a license is valid when it is mentioned or referred to in the same place where you upload your data. Some repositories like Zenodo allow you to select a license, and they make sure it is clear under which license the data are available.
You can apply a license by one of these ways:
- Choosing a license when you upload your data to a repository
- Referring to the license on the webpage where the data are hosted
- Attaching the license to the metadata
- Adding a readme file / license file to your data
The license chooser can help you generate a plain text or html snippet to add to your readme or website.
Note
Specific to climate-related research, CMIP6 explicitly requires you to add the license to the metadata
Key Points
A permissive license ensures the re-usability of your data.
Many big inter-comparison projects already have suitable licenses.
For derived work, existing licenses may restrict your choice of license.
Ownership of data (FIXME)
Conclusion
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How can I assess the FAIRness of my data?
What do I do now to improve the FAIRness of my data?
Objectives
Relate each FAIRification practice with FAIR principles.
Be aware of available tools/resources for assessing FAIRness of your data.
Understand the next steps you can take to improve FAIRness of your data.
FAIRification practices and FAIR principles
We discussed each FAIRification practice, i.e. documentation, metadata, file formats, access to data, persistent identifiers, and data licenses. We also explained what a FAIRification practice means in a FAIR context. In summary:
Make your research findable
- Publish your data and/or metadata in a searchable resource such as a repository that assigns a persistent identifier.
- Include rich accurate machine-readable descriptive metadata and keywords to your data, preferably according to your community standards.
Make your data acessible
- Attach a data license or clear data accessibility statement in your openly available administrative metadata.
- Ensure your data are archived in long-term storage and retrievable by their persistent identifier using a standard protocol.
- Give access to the metadata, even if the data are closed.
Make your data interoperable
- Include sufficient and structural metadata in accordance with your research community’s standards.
- Use common standards, terminologies, vocabularies, and ontologies for the data.
- Prefer open, long-term viable file formats for your data and metadata.
Make your data reusable
- Attach all the relevant contextual information in either the documentation or metadata.
- Include sufficient and structural metadata in accordance with your research community’s standards.
- Prefer open, long-term viable file formats for your data and metadata.
- Apply a machine-readable data license.
This image was created by Scriberia for The Turing Way community and is used under a
CC-BY license. Source: https://doi.org/10.5281/zenodo.3695300
Assessing FAIRness
FAIR is a journey. The FAIR principles are guidelines. A FAIR assessment now is a snapshot in time. Nevertheless, individuals and communities look to how FAIR their data are. The reasons are various, including gaining a better understanding and making improvements. Ultimately, an assessment can be a helpful guide on the path to becoming more FAIR.
The following are some resources and tools to help you get started.
- FAIR-Aware assessment tool.
- Zenodo overview of how the service responds to the FAIR principles.
- A list of resources for the assessment of digital objects provided by FAIRassist.
- Mirror, mirror on the wall, who is the FAIRest one of all?
- The Australian Research Data Commons’ FAIR data self-assessment tool.
Improving FAIRness
We provided recommendations, examples of steps you can take before, during and after your research project to make your research data more FAIR. FAIR sounds like a lot of work. However, here is how you can get started:
- Understand how FAIR translates to your field/community.
- Use standards that are common to your field/community.
- Collaborate with other communities to define a relevant metadata scheme/standards.
- Check the requirements of the repository where data is stored.
Make a checklist for your data
Here are some questions about the use case you chose in the introduction of this tutorial, here.
We have explored FAIR principles. Now, try to make a checklist to discuss:
- how FAIR your research data are.
- what measures could be taken to improve FAIRness of your data.
Finding more guidance to go FAIR
- Follow a framework guiding FAIRification e.g. Three-point FAIRification Framework.
- Have a look at Research Data Management starter kit.
- Ask librarians/expertise in information management for help with the process.
Further Reading
Key Points
FAIRification practices are about documentation, metadata, file formats, access to data, persistent identifiers, and data licenses.
The FAIR principles provide clear handles on data management in the movement towards open and sustainable science.
The FAIR principles promote maximum use of research data, involving all the stakeholders from data producers to funding agencies.