Data cubes with ODC-STAC
Last updated on 2026-04-09 | Edit this page
Overview
Questions
- Can I mosaic tiled raster datasets when my area of interest spans multiple files?
- Can I stack raster datasets that cover the same area along the time dimension in order to explore temporal changes of some quantities?
Objectives
- ODC-STAC allows you to work with raster datasets spanning multiple files as if they were a single multi-dimensional object (a “data cube”).
Introduction
In the previous episodes we worked with satellite images with a fixed boundary on how they have been collected, however in many cases you would want to have an image that covers your area of interest which often does not align with boundaries of the collected images. If the phenomena you are interested in covers two images you could manually mosaic them, but sometimes you are interested in multiple images that overlapping.
ODC-STAC offers functionality that allows you to get a mosaic-ed image based on the a bounding box or a polygon containing the area of interest. In this lesson we show how odc-stac can be employed to re-tile and stack satellite images in what are sometimes referred to as “data cubes”.
Create a data cube with ODC-STAC
As you might have noticed in the previous episodes, the satellite images we have used until now do actually not cover the whole island of Rhodes. They miss the southern part of the island. Using ODC-STAC we can obtain an image for the whole island. We use the administrative boundary of Rhodes to define our area of interest (AoI). This way we are sure to have the whole island.
More important, using ODC-STAC you can also load multiple images (lazy) into one datacube allowing you to perform all kind of interesting analyses as will be demonstrated below.
But first we need to upload the geometry of Rhodes. To do so we use geopandas and load the geometry we previously stored in a geopackage.
Next, we search for satellite images that cover our AoI (i.e. Rhodes) in the Sentinel-2 L2A collection that is indexed in the Earth Search STAC API. Since we are interested the period right before and after the wild fire we include as dates the 1st of July until the 31st of August 2023 :
PYTHON
import pystac_client
api_url = "https://earth-search.aws.element84.com/v1"
collection_id = "sentinel-2-c1-l2a"
client = pystac_client.Client.open(api_url)
search = client.search(
collections=[collection_id],
datetime="2023-07-01/2023-08-31",
bbox=bbox
)
item_collection = search.item_collection()odc-stac
can ingest directly our search results and create a Xarray DataSet
object from the STAC metadata that are present in the
item_collection. By specifying
groupby='solar_day', odc-stac automatically groups and
merges images corresponding to the same date of acquisition.
chunks={...} sets up the resulting data cube using Dask
arrays, thus enabling lazy loading (and further operations).
use_overviews=True tells odc-stac to direcly load
lower-resolution versions of the images from the overviews, if these are
available in Cloud Optimized Geotiffs (COGs). We set the resolution of
the data cube using the resolution argument, and define the
AoI using the bounding box (bbox). We decided to set the
resolution to 20 in order to limit the size of the images a bit.
PYTHON
import odc.stac
ds = odc.stac.load(
item_collection,
groupby='solar_day',
chunks={'x': 2048, 'y': 2048},
use_overviews=True,
resolution=20,
bbox=rhodes.total_bounds,
)odc-stac builds a data cube representation from all the relevant
files linked in item_collection as a Xarray DataSet. Let us
have a look at it:
OUTPUT
<xarray.Dataset> Size: 7GB
Dimensions: (y: 3255, x: 2567, time: 25)
Coordinates:
* y (y) float64 26kB 4.035e+06 4.035e+06 ... 3.97e+06 3.97e+06
* x (x) float64 21kB 5.613e+05 5.613e+05 ... 6.126e+05 6.126e+05
spatial_ref int32 4B 32635
* time (time) datetime64[ns] 200B 2023-07-01T09:10:15.805000 ... 20...
Data variables: (12/18)
red (time, y, x) uint16 418MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
green (time, y, x) uint16 418MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
blue (time, y, x) uint16 418MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
visual (time, y, x) float32 836MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
nir (time, y, x) uint16 418MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
swir22 (time, y, x) uint16 418MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
... ...
scl (time, y, x) uint8 209MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
aot (time, y, x) uint16 418MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
coastal (time, y, x) uint16 418MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
nir09 (time, y, x) uint16 418MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
cloud (time, y, x) uint8 209MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>
snow (time, y, x) uint8 209MB dask.array<chunksize=(1, 2048, 2048), meta=np.ndarray>Working with the data cube
Like we did in the previous episode, let us calculate the NDVI for
our study area. To do so we need to focus on the variables: the red band
(red), the near infrared band (nir) and the
scene classification map (scl). We will use the former two
to calculated the NDVI for the AoI. The latter, we use as a
classification mask provided together with Sentinel-2 L2A products.
In this mask, each pixel is classified according to a set of labels (see
Figure 2 in classification
mask documentation).
First we define the bands that we are interested in:
Next we will use the mask to drop pixels that are labeled as clouds and water. For this we use the classification map to mask out pixels recognized by the Sentinel-2 processing algorithm as cloud or water:
PYTHON
# generate mask ("True" for pixel being cloud or water)
mask = scl.isin([
3, # CLOUD_SHADOWS
6, # WATER
8, # CLOUD_MEDIUM_PROBABILITY
9, # CLOUD_HIGH_PROBABILITY
10 # THIN_CIRRUS
])
red_masked = red.where(~mask)
nir_masked = nir.where(~mask)Then, we calculate the NDVI:
We can visualize the calculated NDVI for the AoI at two given dates (before and after the wildfires) by selecting the date:
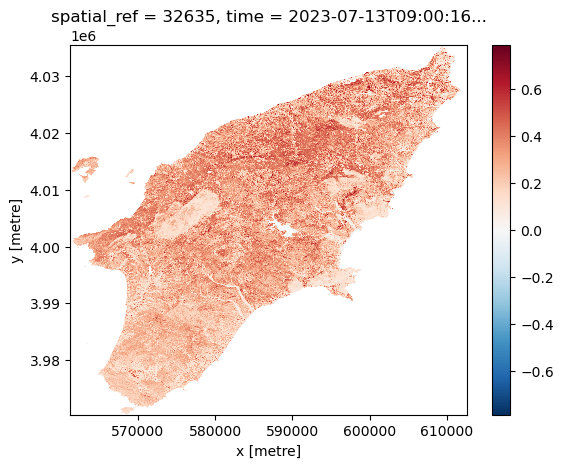
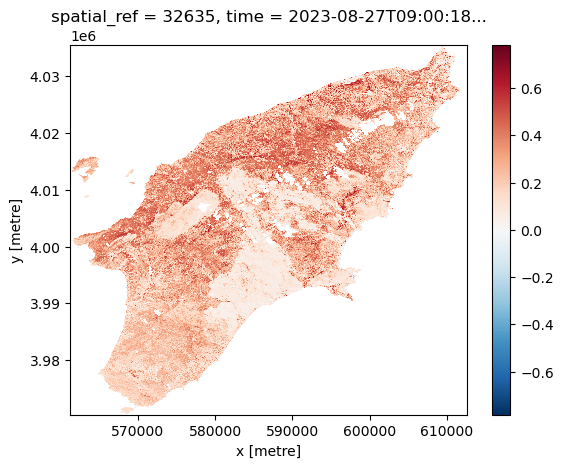
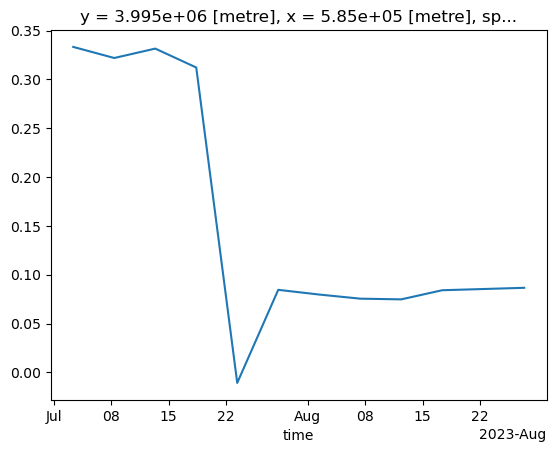
Another feature of having the data available in a datacube is that you can for instance questions multiple layers. If you want for instance to see how the NDVI changed over time for a specific point you can do the following. Let us first define a point in the region where we know it was affected by the wildfile. To check that it is after the fire we plot it:
PYTHON
x = 585_000
y = 3_995_000
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ndvi_after.plot(ax=ax)
ax.scatter(x, y, marker="o", c="k")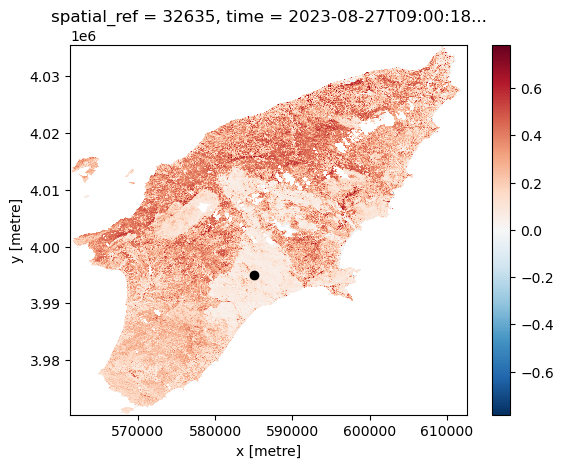
Now let us extract the NDVI values computed at that point for the full time series:
OUTPUT
<xarray.DataArray (time: 25)> Size: 100B
dask.array<getitem, shape=(25,), dtype=float32, chunksize=(1,), chunktype=numpy.ndarray>
Coordinates:
y float64 8B 3.995e+06
x float64 8B 5.85e+05
spatial_ref int32 4B 32635
* time (time) datetime64[ns] 200B 2023-07-01T09:10:15.805000 ... 20...We now trigger computation. Note that we run this in parallel (probably not much of an effect here, but definitely helpful for larger calculations):
OUTPUT
CPU times: user 15.6 s, sys: 4.9 s, total: 20.5 s
Wall time: 1min 8sThe result is a time series representing the NDVI value computed for the selected point for all the available scenes in the time range. We drop the NaN values, and plot the final result: