Parallel raster computations using Dask
Last updated on 2025-02-26 | Edit this page
Estimated time: 55 minutes
Overview
Questions
- How can I parallelize computations on rasters with Dask?
- How can I determine if parallelization improves calculation speed?
- What are good practices in applying parallelization to my raster calculations?
Objectives
- Profile the timing of the raster calculations.
- Open raster data as a chunked array.
- Recognize good practices in selecting proper chunk sizes.
- Setup raster calculations that take advantage of parallelization.
Introduction
Very often raster computations involve applying the same operation to different pieces of data. Think, for instance, to the “pixel”-wise sum of two raster datasets, where the same sum operation is applied to all the matching grid-cells of the two rasters. This class of tasks can benefit from chunking the input raster(s) into smaller pieces: operations on different pieces can be run in parallel using multiple computing units (e.g., multi-core CPUs), thus potentially speeding up calculations. In addition, working on chunked data can lead to smaller memory footprints, since one may bypass the need to store the full dataset in memory by processing it chunk by chunk.
In this episode, we will introduce the use of Dask in the context of
raster calculations. Dask is a Python library for parallel and
distributed computing. It provides a framework to work with different
data structures, including chunked arrays (Dask Arrays). Dask is well
integrated with (rio)xarray, which can use
Dask arrays as underlying data structures.
Dask
This episode shows how Dask can be used to parallelize operations on local CPUs. However, the same library can be configured to run tasks on large compute clusters.
More resources on Dask:
- Dask and Dask Array.
- Xarray with Dask.
It is important to realize, however, that many details determine the extent to which using Dask’s chunked arrays instead of regular Numpy arrays leads to faster calculations (and lower memory requirements). The actual operations to carry out, the size of the dataset, and parameters such as the chunks’ shape and size, all affects the performance of our computations. Depending on the specifics of the calculations, serial calculations might actually turn out to be faster! Being able to profile the computational time is thus essential, and we will see how to do that in a Jupyter environment in the next section.
Introduce the Data
We will use satellite images from the search that we have carried out in the episode: “Access satellite imagery using Python”. Briefly, we have searched for Sentinel-2 scenes of Rhodes from July 1st to August 31st 2023 that have less than 1% cloud coverage. The search resulted in 11 scenes. We focus here on the most recent scene (August 27th), since that would show the situation after the wildfire, and use this as an example to demonstrate parallel raster calculations.
For your convenience, we have included the scene of interest among
the datasets that you have already downloaded when following the setup instructions. You should, however, be
able to download the satellite images “on-the-fly” using the JSON
metadata file that was created in the
previous episode (the file rhodes_sentinel-2.json).
If you choose to work with the provided data (which is advised in case you are working offline or have a slow/unstable network connection) you can skip the remaining part of the block and continue with the following section: Dask-powered rasters.
If you want instead to experiment with downloading the data
on-the-fly, you need to load the file
rhodes_sentinel-2.json, which contains information on where
and how to access the target satellite images from the remote
repository:
You can then select the first item in the collection, which is the most recent in the sequence:
OUTPUT
<Item id=S2A_35SNA_20230827_0_L2A>In this episode we will consider the red and near infrared bands
associated with this scene. We extract the URL / href
(Hypertext Reference) that point to each of the raster files, and store
these in variables that we can use later on instead of the raster data
paths to access the data:
Dask-powered rasters
Chunked arrays
As we have mentioned, rioxarray supports the use of
Dask’s chunked arrays as underlying data structure. When opening a
raster file with open_rasterio and providing the
chunks argument, Dask arrays are employed instead of
regular Numpy arrays. chunks describes the shape of the
blocks which the data will be split in. As an example, we open the red
band raster using a chunk shape of (1, 4000, 4000) (block
size of 1 in the first dimension and of 4000
in the second and third dimensions):
PYTHON
import rioxarray
red = rioxarray.open_rasterio("data/sentinel2/red.tif", chunks=(1, 4000, 4000))Xarray and Dask also provide a graphical representation of the raster data array and of its blocked structure.
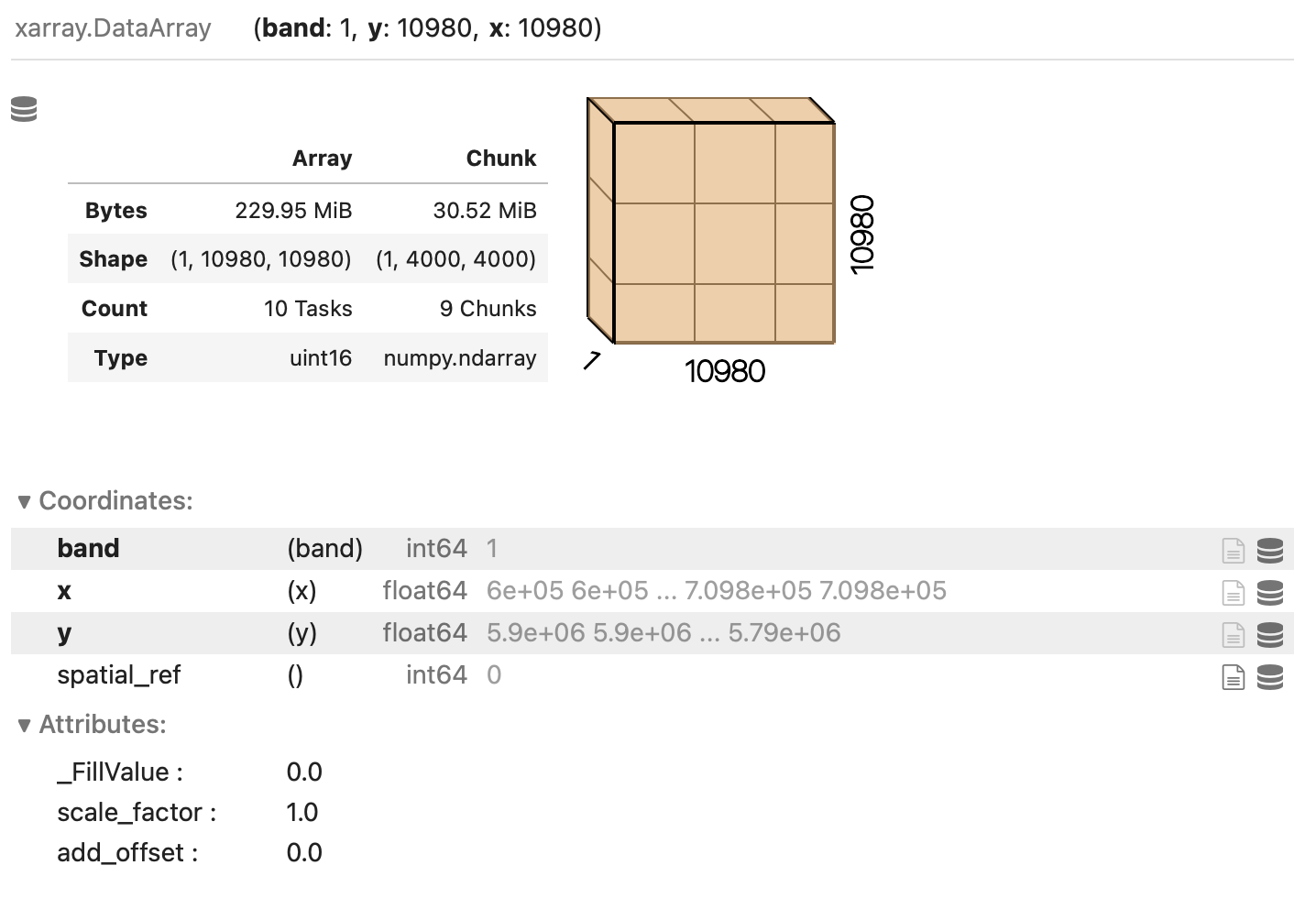
Exercise: Chunk sizes matter
We have already seen how COGs are regular GeoTIFF files with a special internal structure. Another feature of COGs is that data is organized in “blocks” that can be accessed remotely via independent HTTP requests, enabling partial file readings. This is useful if you want to access only a portion of your raster file, but it also allows for efficient parallel reading. You can check the blocksize employed in a COG file with the following code snippet:
PYTHON
import rasterio
with rasterio.open("/path/or/URL/to/file.tif") as r:
if r.is_tiled:
print(f"Chunk size: {r.block_shapes}")In order to optimally access COGs it is best to align the blocksize of the file with the chunks enployed when loading the file. Which other elements do you think should be considered when choosing the chunk size? What do you think are suitable chunk sizes for the red band raster?
PYTHON
import rasterio
with rasterio.open("data/sentinel2/red.tif") as r:
if r.is_tiled:
print(f"Chunk size: {r.block_shapes}")OUTPUT
Chunk size: [(1024, 1024)]Ideal chunk size values for this raster are multiples of 1024. An
element to consider is the number of resulting chunks and their size.
While the optimal chunk size strongly depends on the specific
application, chunks should in general not be too big nor too small
(i.e. too many). As a rule of thumb, chunk sizes of 100 MB typically
work well with Dask (see, e.g., this blog
post). Also, the shape might be relevant, depending on the
application! Here, we might select a chunks shape of
(1, 6144, 6144)::
which leads to chunks 72 MB large: ((1 x 6144 x 6144) x 2 bytes /
2^20 = 72 MB). Also, we can let rioxarray and Dask figure out
appropriate chunk shapes by setting chunks="auto":
which leads to (1, 8192, 8192) chunks (128 MB).
Parallel computations
Operations performed on a DataArray that has been opened
as a chunked Dask array are executed using Dask. Dask coordinates how
the operations should be executed on the individual chunks of data, and
runs these tasks in parallel as much as possible.
Let us set up an example where we calculate the NDVI for a full Sentinel-2 tile, and try to estimate the performance gain by running the calculation in parallel on a multi-core CPU.
To run the calculation serially, we open the relevant raster bands, as we have learned in the previous episodes:
PYTHON
red = rioxarray.open_rasterio('data/sentinel2/red.tif', masked=True)
nir = rioxarray.open_rasterio('data/sentinel2/nir.tif', masked=True)We then compute the NDVI. Note the Jupyter magic %%time,
which returns the time required to run the content of a cell (note that
commands starting with %% needs to be on the first line of
the cell!):
OUTPUT
CPU times: user 4.99 s, sys: 3.44 s, total: 8.43 s
Wall time: 8.53 sWe note down the calculation’s “Wall time” (actual time to perform the task).
Now we run the same task in parallel using Dask. To do so, we open the relevant rasters as chunked arrays:
PYTHON
red_dask = rioxarray.open_rasterio('data/sentinel2/red.tif', masked=True, lock=False, chunks=(1, 6144, 6144))
nir_dask = rioxarray.open_rasterio('data/sentinel2/nir.tif', masked=True, lock=False, chunks=(1, 6144, 6144))Setting lock=False tells rioxarray that the
individual data chunks can be loaded simultaneously from the source by
the Dask workers.
We now continue to the actual calculation: Note how the same syntax as for its serial version is employed for computing the NDVI. Don’t forget to add the Jupyter magic to record the timing!
OUTPUT
CPU times: user 7.71 ms, sys: 1.71 ms, total: 9.42 ms
Wall time: 8.61 msDid we just observe a 1000x speed-up when comparing to the serial calculation (~8 s vs ~8 ms)? Actually, no calculation has run yet. This is because operations performed on Dask arrays are executed “lazily”, i.e. they are not immediately run.
Dask graph
The sequence of operations to carry out is stored in a task graph, which can be visualized with:
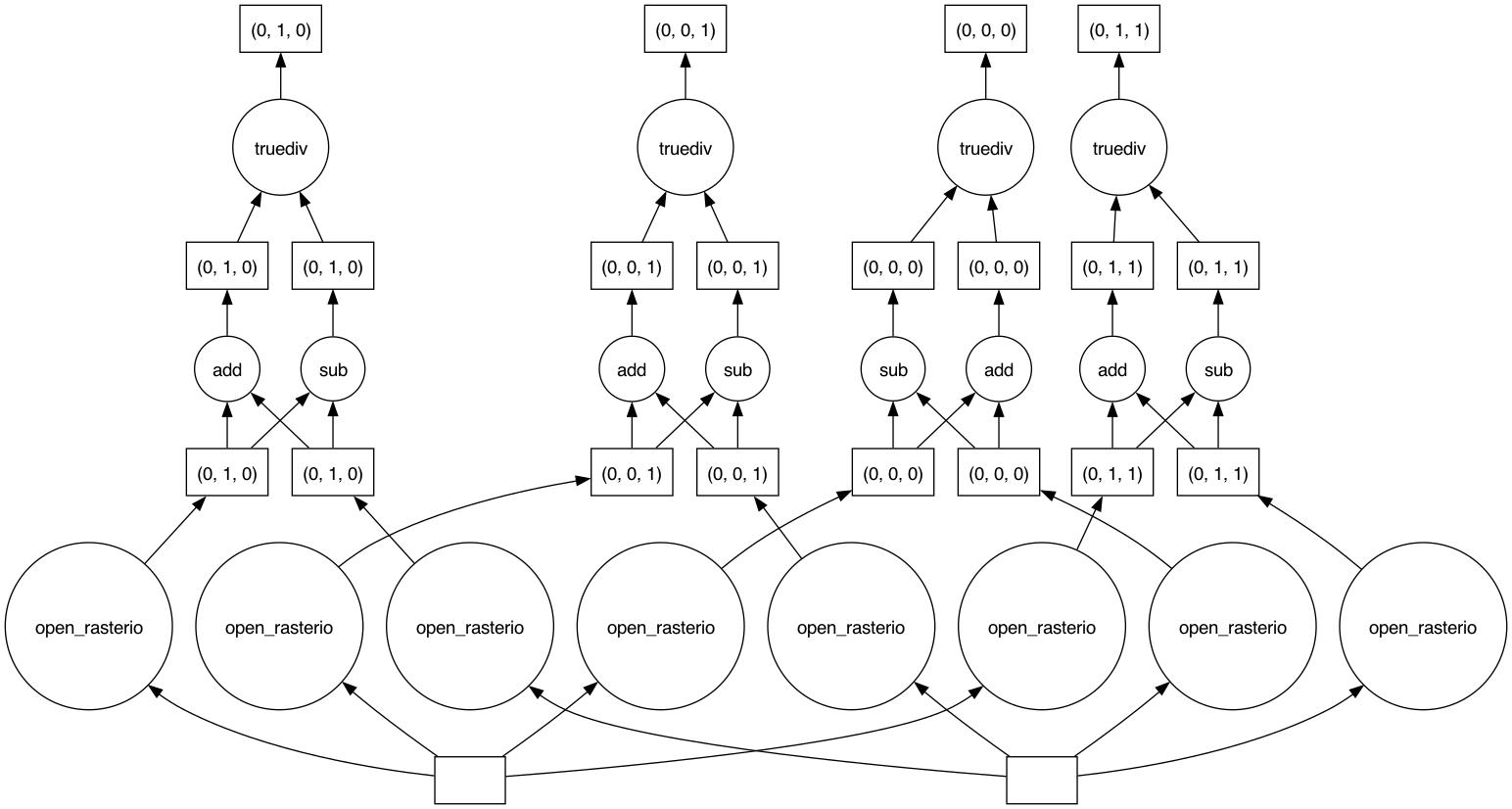
The task graph gives Dask the complete “overview” of the calculation, thus enabling a better management of tasks and resources when dispatching calculations to be run in parallel.
Most methods of DataArray’s run operations lazily when
Dask arrays are employed. In order to trigger calculations, we can use
either .persist() or .compute(). The former
keeps data in the form of chunked Dask arrays, and it should thus be
used to run intermediate steps that will be followed by additional
calculations. The latter merges instead the chunks in a single Numpy
array, and it should be used at the very end of a sequence of
calculations. Both methods accept the same parameters. Here, we
explicitly tell Dask to parallelize the required workload over 4
threads. Let’s again time the cell execution:
OUTPUT
CPU times: user 4.18 s, sys: 2.19 s, total: 6.37 s
Wall time: 2.32 sThe timing that we have recorded makes much more sense now. When running the task on a 4-core CPU laptop, we observe a x3.6 speed-up when comparing to the analogous serial calculation (8.53 s vs 2.32 s).
Once again, we stress that one does not always obtain similar performance gains by exploiting the Dask-based parallelization. Even if the algorithm employed is well suited for parallelization, Dask introduces some overhead time to manage the tasks in the Dask graph. This overhead, which is typically of the order of few milliseconds per task, can be larger than the parallelization gain. This is the typical situation with calculations with many small chunks.
Finally, let’s have a look at how Dask can be used to save raster
files. When calling .to_raster(), we provide the as
additional argument lock=threading.Lock(). This is because
the threads which are splitting the workload must “synchronise” when
writing to the same file (they might otherwise overwrite each other’s
output).
Note that .to_raster() is among the methods that trigger
immediate calculations (one can change this behaviour by specifying
compute=False).
- The
%%timeJupyter magic command can be used to profile calculations. - Data ‘chunks’ are the unit of parallelization in raster calculations.
- (
rio)xarraycan open raster files as chunked arrays. - The chunk shape and size can significantly affect the calculation performance.
- Cloud-optimized GeoTIFFs have an internal structure that enables performant parallel read.